A disturbing thing is that the architecture is much less novel than I originally thought it would be, so this shows perhaps one of the major difficulties was having the resources to try different things on a massive set of multiple alignments. This is something an industrial lab like DeepMind excels at. Whereas universities tend to suck at anything that requires a directed effort of more than a handful of people.
>A disturbing thing is that the architecture is much less novel than I originally thought it would be, so this shows perhaps one of the major difficulties was having the resources to try different things on a massive set of multiple alignments.
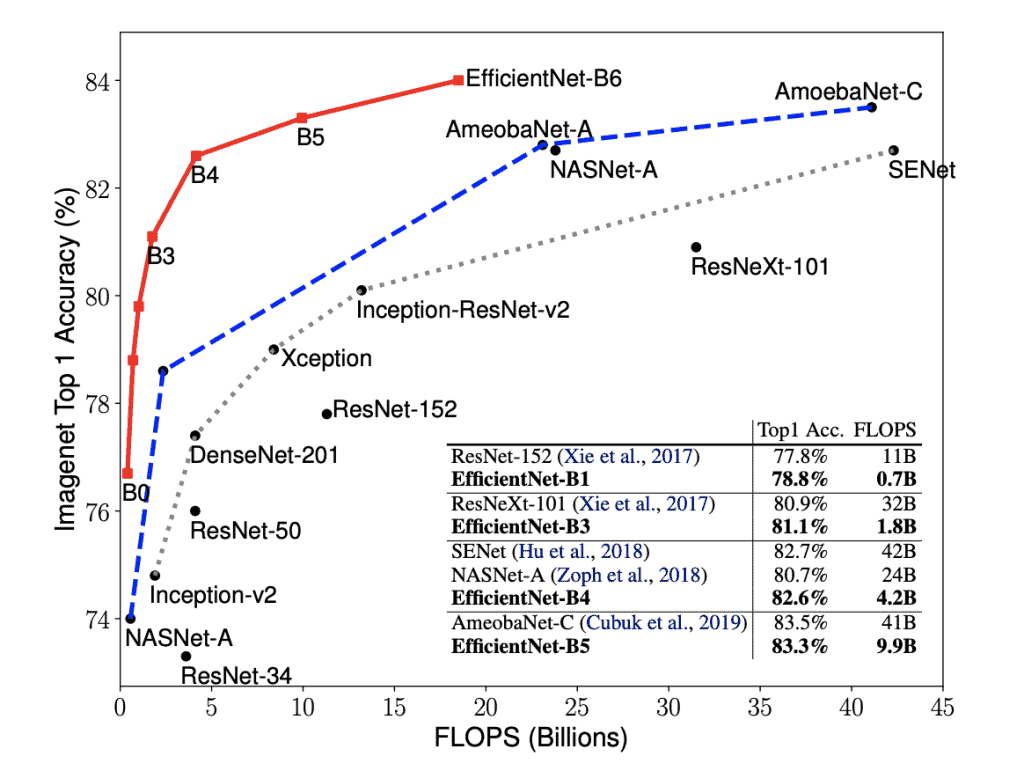
Most of the compute in ML research seems to be going into architecture search. Once the architecture is found, training and net finetuning/transfer learning is comparatively cheap, and then inference is cheaper still. This implies we could see 10-100x gains in AI algorithms using today's hardware, or sudden surprising appearance of AI dominance in an unexpected field. (Object grasping in unstructured environments? Art synthesis?) A task could go from totally impossible to trivial in a year. In retrospect, the EfficientNet scaling graph should have alarmed more people than it did: https://learnopencv.com/wp-content/uploads/2019/06/Efficient...
Waymo has been puttering along for years, not announcing much of interest. This may have caused some complacency about self-driving cars, which is a mistake. Algorithms only get better, while humans stay the same. Once Waymo can replace some human drivers some of the time, things will start changing very quickly.
Self-driving is a cursed problem, but the thorniest obstacles relate to optics and politics and not technology. AI can already replace some human drivers some of the time; but it doesn’t matter because each news story about a Tesla killing a passenger or driving into a parked fire truck sets back public acceptance of self-driving cars by years.
True, and Tesla is so far behind competitors when it comes to self driving that they knowingly push the envelope, because either they succeed, or they kill their customers but hurt all self-driving companies. So both scenarios work to their advantage and they just pay the minor fines and compensations to the people the kill in the process. And the Elon posts some Tweets blaming the people who got killed and his fandome happily cheers.
There is a reason Waymo is progressing at what looks like snail speed from outside observers, and that reason is that it’s the only ethical pace for development and testing of what could eventually become broadly available fully autonomous vehicles.
Teslas philosophy is that self driving is useless if it can't handle every road and route out there, while Waymo who already has a ride hailing service, relies on pre-mapped routes and databases.
Both have their advantages and disadvantages. Waymo requires huge databases and a constant network connection. But it's good enough to be used in real-life without a backup driver, in certain select locations that is. If there's a road construction somewhere, don't expect the Waymo car to handle it unless they update their database.
Tesla on the other hand attempts to solve the problem with minimal database use, where most of the info coming from road markings and traffic signs. A much harder problem.
Going slowly may mean fewer people die directly. But I think it’s useful to remember that every year we delay being able to replace human drivers means that roughly a million lose their lives worldwide in auto accidents, and many more are maimed, many permanently.
It’s obviously complex, though, bad PR likely delays things as well.
> Most of the compute in ML research seems to be going into architecture search.
No it's not. Only Google spends significant time with automatic architecture search, and many people think this is really to try to sell cloud capacity.
> Once the architecture is found, training and net finetuning/transfer learning is comparatively cheap
Training isn't cheap for significant problems.
Getting the data is very expensive, and compute is a significant expense for large datasets.
> This implies we could see 10-100x gains in AI algorithms using today's hardware
Actually, most of the time we see 10-100% (percent! not times) gains from architecture improvements, whether they be manual or automatic.
But that is very significant, because a 10% improvement can suddenly make something useful that wasn't before.
>No it's not. Only Google spends significant time with automatic architecture search, and many people think this is really to try to sell cloud capacity.
Maybe not automatic architecture search but a lot does go into testing different architectures and changes to them in a more manual manner. Though yes, those tests are run on a smaller scale so for those huge models, training will be a bigger portion compared to architecture search than for smaller models.
If you don't you might not realize they are comparing ResNet (designed for ultimate performance) vs EffcientNet to show how close it gets in accuracy in the FLOPs budget.
Note that the best accuracy for EffcientNet is roughly 1-2% better than ResNet/ResNeXT/SENet/etc but does have a much better FLOPs budget.
But these other architectures were never optimised for FLOPs. It wasn't event a consideration when designing them.
And EffcientNet is about a (manually designed) technique for scaling neural networks up in accuracy. Only EffcientNet-B0 is designed by AutoML, the others are scaled up. See the paper[1] for complete details.
Like-for-like should be against MobileNet etc. EfficentNet is better, but the comparison is more reasonable in general.
> A disturbing thing is that the architecture is much less novel than I originally thought it would be, so this shows perhaps one of the major difficulties was having the resources to try different things on a massive set of multiple alignments. This is something an industrial lab like DeepMind excels at. Whereas universities tend to suck at anything that requires a directed effort of more than a handful of people.
Yeah, the HN commentary on Alphafold has a high heat-to-light ratio. I'm eager to read the paper because the previous description of the method sounded remarkably similar to methods that have been around for ages, plus a few twists.
The devil is going to be in the details on this one.
It means that the conversation isn't producing much of value despite lots of activity, like an inefficient lightbulb that wastes energy by emitting heat instead of light.
Incandescent light bulbs are generally very inefficient in producing light, compared to LED for example. They produce a lot of heat and not much light for which they are made.
So in this context I suppose that gp implies that these threads don't provide much meaningful discussion but rather lots of hand waving.
It’s trying to say light is more valuable than heat, or some such folksy thing. I cook steak in the dark so I don’t find it to be a very insightful metaphor.
Transformers seem to be the successor to conv nets. But in my direct experience advocating for them, it's amazing how reluctant industry peeps were to trying them because they associated all the limitations of LSTM networks with them for a long time. YMMV, but that's how it went with me.
I even predicted DeepMind's CASP 14 network would be transformer-based back in 2018, but I couldn't have told you the details of that transformer, just that it was a no-brainer to move from fixed width convolutions to arbitrary width attention sums because sequence motifs and long-range interactions are of arbitrary width in the sequence.
All that seems to have changed with AlphaFold 2 because unlike GPT-XXX, this isn't a parlor trick with memorized text. This is actually useful and the FOSSing of the network will spawn all sorts of new applications of the approach.
So now I wonder what will replace Transformers because nothing lasts forever and there are a lot of smart people trying all sorts of new ideas.
The key difference seems to be using the multiple alignments and assumption about evolutionary conservation? Useful for genes conserved, but less useful for de-novo proteins (like COVID and cancer) I guess?
Dunno yet. MSAs were always a key input to Rosetta (previous best method). How they were used was very different.
Fundamentally, everything in this space (= non-physical methods) is about inferring structure from things that are closely related. And you can't solve the problem at all for non-trivial proteins using physics, so here we are.
I guess poster is referring to purely using physics to work out the structure - i.e. no more knowledge than how atoms/molecules move and the sequence. At the moment knowledge is gleaned from evolution by virtue of evolutionary conservancy.
Essentially yes. In theory, you could start from quantum mechanics and get the structure of any chemical matter. In practice, that's intractable. So there has been decades of work to make ever-simpler, less expensive approximations, and use these models of forces/energies to predict the structures of complex biomolecules.For example, google "molecular mechanics" or "molecular dynamics", and you'll find discussion o f things like the van der waals model of an atom, models of chemical bonds that resemble springs from physics 101, coulomb's law, and so on.
People take these simple models, chain them together in different ways, adjust the free parameters (i.e. weights) by fitting to known data, and thus create "force fields" that can be used to estimate the energies and/or forces on a molecule, given only the coordinates of the atoms. These methods work OK for some limited problems, but tend to fly off the rails as simulation times get longer, or if atomic systems have more electrostatics, motion, "weird" atoms (like heavy metals), etc.
This (Alphafold) kind of work is completely different, in that it starts from data, and uses the physical models only to do final refinements (if at all).
That's the case with basically everything DeepMind does. They have a very good PR department which hypes up everything they do while conveniently ignoring that basically nothing of any practical consequence has come of their endeavors. But I do think it's important that these companies exist now so we can see what not to try going forward.
Well, the CASP14 results do speak for themselves. Protein structure prediction is not necessarily of great meaning to drug discovery or biology, but they pretty much blew everyone else out of the water in a fair contest. For that reason, they deserve praise.
It's a little like making a robot that is very, very good at something pointless (say, using a yo-yo). Who knows where it might lead, but if they make the best damned yo-yo bot in the world, they deserve whatever praise they get from the yo-yo community.
Their PR strategy is to take problems people thought were impossible to solve in the next 10 years, and solve them (Go) or nearly solve them (StarCraft 2, protein solving)
No one thought that Go was impossible except people who weren't involved in engineering/software and shouldn't have been taken seriously in the first place.
Superhuman game AI has existed for decades. It's entirely unsurprising that one can play a strategy game, and no one thought it wasn't possible.
I'll send you $500 USD if AlphaFold derivatives lead to a single new therapy or drug that helps real patients in the next 5 years.
'In the next 10 years' is the key phrase here. Everyone watching Go (I looked at the problem 15-ish years ago) thought it required a massive advance to beat the best humans. DeepMind made that advance.
'bah, whatever, both Newton and Leibniz were hacks. Everyone knew calculus would have been invented anyway. It's basically a consequence of some stuff Archimedes did.'
DM didn't "solve" anything around proteins. They just made an improvement to existing homology modelling methods. If you look, the system is incredibly dependent on having large numbers of high quality sequence alignments to proteins with known structure and lots and lots of evolutionary data.
This was actually fairly obvious 20 years ago and it's been disappointing to me to see how long it took somebody to make this improvement, but really, it couldn't have been done without recent algorithmic improvements and huge amounts of CPU time.
Well here's one example: Deepmind made Wavenet, which turned text-to-speech on it's head. Variants of Wavenet underlie most or all of the talking machines (Google assistant, Alexa, etc.).
Well, also Alpha-Fold, and let's not forget beating the world champions at Go, which was a really major unsolved problem. I'll also contend that WaveNet was not 'maybe-slightly-better,' but actually a massive leap forward.
The phrase 'who pissed in your cheerios' comes to mind... Here's hoping that if you ever build something worthwhile it is received with a bit more compassion.
I haven't read the full paper but there is certainly some new/exciting developments i'm seeing just from scanning. The “Invariant Point Attention" which is described as a novel, geometry-aware and equivariant attention operation is pretty huge.
Something along these lines was speculated to be to be used by Fabian Fuchs [0] soon after the original CASP competition. Basically, it's a huge win for the geometric deep learning people, and indicates an exciting direction for mainstream academia to move in.
I'm genuinely curious: could the output of Alphafold be fed into a classical folding algorithm (as a starting point), or is the output of Alphafold too far down the wrong path, in these cases?
many of these resources are available, it's mostly that academic scientists don't have the time, money, or expertise to manage large datasets. However, the community has maintained high quality MSA database for decades and that's exactly the work that DM drafted off.
> academic scientists don't have the time, money, or expertise to manage large datasets
I may be cynical about general expertise, as a support person, but large datasets have long been stock in trade of areas I'm more or less familiar with, whether "large" is TBs or PBs like CERN experiments. (When I were a lad, it was what you could push past the tape interface in a few days -- data big in cubic feet...)
Tape is worthless except for archival purposes (and it's not particularly good). it should not be the constraint on the dataset (IE, any important dataset should already be in live serving with replication).
Very few players wrangle petabytes effectively. Many players have petabytes, but they're just piles of disorganized data that couldn't be used for training ML. Moving petabytes is still a huge pain and few folks have proficiency in giving ML algorithms high performance access to the data.
{kind=link}
For example, multi-complex proteins are not well predicted yet and these are really important in many biological processes and drug design:
https://occamstypewriter.org/scurry/2020/12/02/no-deepmind-h...
A disturbing thing is that the architecture is much less novel than I originally thought it would be, so this shows perhaps one of the major difficulties was having the resources to try different things on a massive set of multiple alignments. This is something an industrial lab like DeepMind excels at. Whereas universities tend to suck at anything that requires a directed effort of more than a handful of people.